
這個專案的目標主要是為了處理excel以及Libreoffice - Calc (ODS格式)
表個文件的專案
因為表格文件在我們日常生活中廣泛應用
除了文書使用的數據統計、記帳處理以外還有許多資料控管可以使用
簡單來說~
我們透過python的目的就是透過程式幫我們管理這些表格文件的應用
畢竟工程師能多懶就要有多懶惰
| 學習目的 | 具體目的 | 範例 |
|---|---|---|
| Part1-自動化 Excel/Calc 操作 | 自動化創建、讀取、修改和保存 Excel 文件 | 自動生成報表、批量修改數據、自動填寫特定欄位 |
| Part2-高效的數據處理 | 快速處理大量 Excel 資料 | 提取特定行或列、合併多個 Excel 文件、計算統計數據 |
| Part3-數值運算與資料分析 | 進行複雜的數學計算,支持大規模數據分析 | 應用複雜數學公式、處理大規模數據矩陣 |
| Part4-數據清理和轉換 | 清理不完整或不一致的 Excel 數據 | 處理缺失數據、重命名欄位、合併多個文件 |
| Part5數據可視化和報告生成 | 從 Excel 數據生成可視化圖表,快速生成報告 | 轉換數據為直方圖、折線圖、餅圖,導出圖表至報告 |
| Part6大量數據處理和分析 | 高效處理超大數據集,避免手動操作中的低效和錯誤 | 分析數萬或數百萬行數據,快速生成統計結果 |
主要是根據這六個parts來學習~
使用 openpyxl、pandas 和 numpy 來操作 Excel 的目的是通過自動化、高效的數據處理和分析來提升工作效率,避免手動操作中的錯誤,並實現更複雜的數據處理需求,這對於任何需要處理大量資料的人來說都是非常重要的技能。
麻煩大家可以先使用pip install openpyxl pandas numpy 一次安裝三個Library
tips - 許多程式指令可以透過空格來一次進行多個安裝
例如:
1.apt install package1 package2 linux 套件安裝指令
2.npm install lib1 lib2 nodejs 套件安裝指令
| 庫名稱 | 功能描述 | 使用場景 |
|---|---|---|
| openpyxl | 專門用於讀取和寫入 Excel 文件,支持單元格、行、列的基本操作。 | 需要處理 Excel 文件的基本操作,如創建、修改和格式化電子表格。 |
| Pandas | 提供強大的數據結構(如 DataFrame 和 Series),適合數據清洗、過濾和分析。 | 進行複雜數據分析和處理,如合併多個數據集、計算統計數據等。 |
| NumPy | 提供高效的數值計算功能,支持多維數組和矩陣運算。 | 進行數學運算、線性代數計算或處理大型數據集的數值計算。 |
心得 - 學習資料處理時對這三個套件使用時機的疑問整理1.openxl : 可以讀取excel文件做處理以及基本操作,但不能做高階數學運算。 2.panda : 也可以讀取excel檔案,但效能會稍微偏低。如果大檔還是會先透過openxl操作檔案輸入/輸出 3.Numpy : 不能直接讀取excel file,但有很多超強的數學公式可以計算處理
綜合以上所述,我們還是會搭配操作使用喔~!
就像是雖然瑞士刀很厲害,但在處理特定功能使用特定廚具,處理食材的效率跟品質會更棒!
今天會使用liberoffice的calc來代替excel預覽
是很好用的開源文件處理工具。
雖然excel的功能強大,不過畢竟是企業提供的軟體。
所以這邊提供給大家做開發練習可以省去一些成本來開發!
有意點像是寫網頁API CRUD的感覺
這邊也是要帶大家先創建、讀取、更新、刪除的對文件的基本操作。
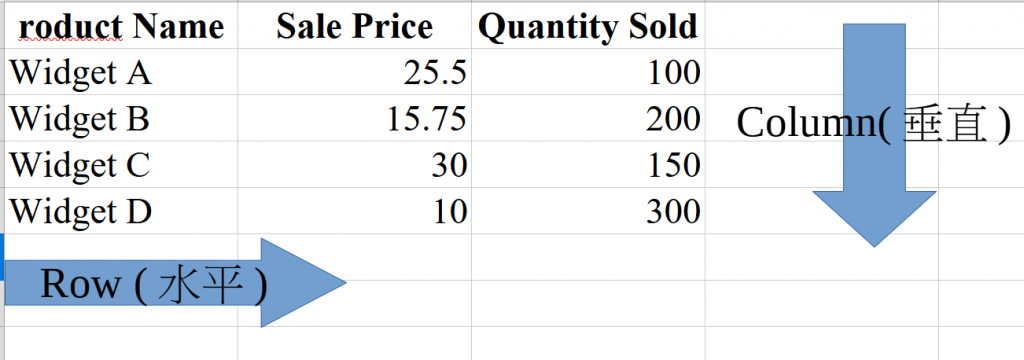
這是待會要做示範的資料,我們先看看怎麼讀這文件的方向。
雖然以一般文書人員處理excel除非是常用excel公式否則方向不需要特別注意。
不過對工程師就有差了
tips1. 因為讀取方式跟程式執行方式有關會以由左到右,有上到下執行2.第一個row先執行1~n個資料,再來執行第二個row以此類推3.這個重點在邏輯的增刪修改資料有重大的幫助4.台灣是橫列直行,但大陸是相反的。為了避免混淆以英文來記5.英文,水平(橫向)是row,垂直(縱向)是column
今天我想要創建一個名稱、價格跟數量的表格如下要怎麼操作呢?
分別給大家看openxl跟panda的範例
| Product Name | Sale Price | Quantity Sold |
|---|---|---|
| Widget A | 25.50 | 100 |
| Widget B | 15.75 | 200 |
| Widget C | 30.00 | 150 |
| Widget D | 10.00 | 300 |
openxl選手import openpyxl
# 創建一個新的 Excel 工作簿
workbook = openpyxl.Workbook()
sheet = workbook.active
# 設置標題行
sheet['A1'] = 'Product Name'
sheet['B1'] = 'Sale Price'
sheet['C1'] = 'Quantity Sold'
# 添加數據
data = [
['Widget A', 25.50, 100],
['Widget B', 15.75, 200],
['Widget C', 30.00, 150],
['Widget D', 10.00, 300]
]
# 把陣列後面的資料加在first row後面
for row in data:
sheet.append(row)
# 保存工作簿
workbook.save('example.xlsx')
這邊有幾個跟python無關,屬於openxl的語法
所以來說明一下XDD
1.1建立工作簿跟工作表
# 創建一個新的工作簿
workbook = Workbook()
# 獲取活動工作表
sheet = workbook.active
1.2標題行(也是列表文件的first row)
# 設置標題行
sheet['A1'] = 'Product Name'
sheet['B1'] = 'Sale Price'
sheet['C1'] = 'Quantity Sold'
也就是工作表中A1格子的名稱是Product Name
1.3塞入資料
# 添加數據
data = [
['Widget A', 25.50, 100],
['Widget B', 15.75, 200],
['Widget C', 30.00, 150],
['Widget D', 10.00, 300]
]
# 塞入資料
for row in data:
sheet.append(row)
這段程式碼的功能是將 data 中的每一行數據逐行添加到 Excel 工作表中。
以下是詳細解釋以及如何印出每層迴圈的資料。
程式碼解析for row in data::
這是一個迴圈,遍歷 data 中的每一行。data 是一個包含多行數據的列表(例如,列表的列表)。
每次迴圈執行時,row 變量將包含 data 中的一行數據。sheet.append(row):
這行程式碼將當前的 row 添加到 Excel 工作表中。append() 方法會將 row 的所有元素依次放入工作表的下一個可用行中。
可以把row print出來就是這樣
['Widget A', 25.5, 100]
['Widget B', 15.75, 200]
['Widget C', 30.0, 150]
['Widget D', 10.0, 300]
1.4塞入資料
# 保存工作簿
workbook.save('example.xlsx')
這邊比較簡單就是openxl 把工作簿存檔
import pandas as pd
# 創建數據
data = {
'Product Name': ['Widget A', 'Widget B', 'Widget C', 'Widget D'],
'Sale Price': [25.50, 15.75, 30.00, 10.00],
'Quantity Sold': [100, 200, 150, 300]
}
# 創建 DataFrame
df = pd.DataFrame(data)
# 保存 DataFrame 到 Excel 文件
df.to_excel('example.xlsx', index=False)
其實就這邊來說沒有太大差異。
在後續read、update跟delete還有資料處理比較有感覺。
前面有提到過了讀取可以透過openxl 跟 panda來讀取。
接下來就讓大家直接看怎麼讀取吧?
import openpyxl
# 讀取 Excel 文件
workbook = openpyxl.load_workbook('example.xlsx')
sheet = workbook.active
# 將數據存儲為二維陣列
data = []
for row in sheet.iter_rows(values_only=True):
data.append(list(row))
print(data)
import pandas as pd
# 讀取 Excel 文件並轉換為 DataFrame
df = pd.read_excel('example.xlsx')
print(df)
等等~看起來是有差程式碼沒錯?但感受不到使用熊貓的好處在哪?
別急? 讓你們看看真正的魔術
大魔術熊貓麻婆(X)
魔術秀正要開始
import openpyxl
# 讀取 Excel 文件
workbook = openpyxl.load_workbook('example.xlsx')
sheet = workbook.active
# 將數據存儲為二維列表
data = []
for row in sheet.iter_rows(values_only=True):
data.append(row)
# 顯示數據
for row in data:
print(row)
# 獲取特定列的最大值(假設 'Sale Price' 在第二列)
sale_prices = [row[1] for row in data[1:]] # 跳過標題行
max_sale_price = max(sale_prices)
print(f'Max Sale Price: {max_sale_price}')
import pandas as pd
# 讀取 Excel 文件並將其轉換為 DataFrame
df = pd.read_excel('example.xlsx')
# 顯示 DataFrame 的內容
print(df)
# 獲取某一列的最大值
max_value = df['Sale Price'].max()
print(f'Max Sale Price: {max_value}')
有沒有感受到差異了?
雖然還沒交到資料處理
但是可以看到透過熊貓處理二維數據的專業可以快速找到最大值
但是透過openxl你必須透過實作演算法(搜尋)去尋找最大值
| 特性 | openpyxl | Pandas |
|---|---|---|
| 數據結構 | 列表的列表(list of lists) | DataFrame |
| 數據類型處理 | 原始格式,不自動轉換 | 自動進行類型轉換 |
| 索引管理 | 無自動索引,需要手動管理 | 自動提供行索引和列標籤 |
| 功能性 | 基本的讀寫操作 | 提供豐富的數據操作和分析功能 |
總結
Pandas 是一個強大的數據分析工具,適合用於需要進行複雜操作和分析的場景。它能夠輕鬆地將 Excel 數據導入到 DataFrame 中,並提供多種方便的方法來處理和分析數據。
openpyxl 更適合於直接操作 Excel 文件,如創建、修改和格式化單元格。它在處理基本的 Excel 操作時表現良好,但不如 Pandas 在數據分析方面強大。
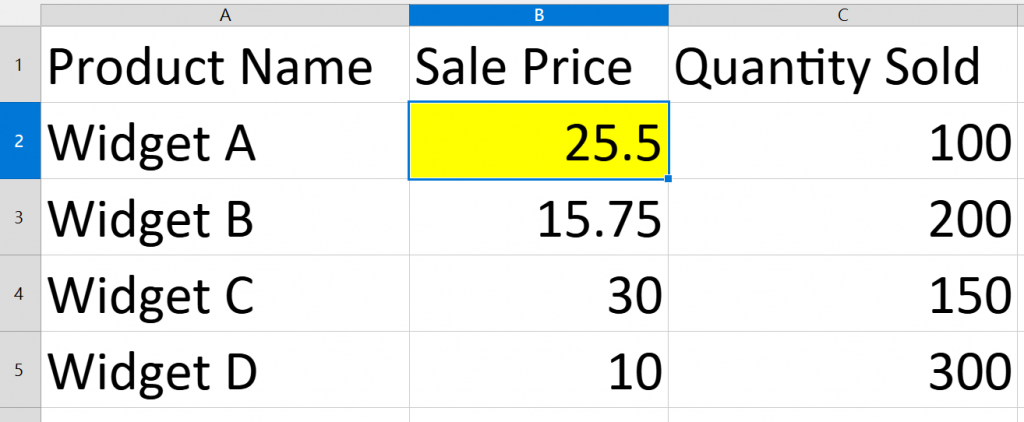
今天假設店長需求是修改Widget A的 Sale Price 變成27.00
我們可以這樣做
from openpyxl import load_workbook
# 載入現有的 Excel 文件
workbook = load_workbook('example.xlsx')
sheet = workbook.active
# 修改特定單元格的值
sheet['B2'] = 27.00 # 將 Widget A 的價格修改為 27.00
# 保存修改後的工作簿
workbook.save('example_modified_openpyxl.xlsx')
我們可以很直覺的知道那個位置在B2 => 因為人類很直覺看到是這個位置如果不用程式修改,操作者也是這樣做的 => 先埋個伏筆
import pandas as pd
# 載入現有的 Excel 文件
df = pd.read_excel('example.xlsx')
# 修改特定單元格的值(假設 'Product Name' 在第一列,'Sale Price' 在第二列)
df.loc[df['Product Name'] == 'Widget A', 'Sale Price'] = 27.00 # 將 Widget A 的價格修改為 27.00
# 保存修改後的 DataFrame 到 Excel 文件
df.to_excel('example_modified_pandas.xlsx', index=False)
總結
| 特性 | openpyxl | Pandas |
|---|---|---|
| 數據結構 | 使用工作簿和工作表對象 | 使用 DataFrame 對象 |
| 修改方式 | 通過直接指定單元格來修改 | 通過 DataFrame 的行和列標籤進行修改 |
| 功能性 | 適合簡單的讀寫操作,支持格式化 | 提供豐富的數據操作和分析功能 |
| 性能 | 適合小型或中型文件 | 更適合處理大型數據集 |
等等? 怎麼看起來 openxl比較簡單
其實這是一個寫程式的新手盲點
我們應該要考慮的一個重要點是資料存在的位置
這個觀念至關重要
會影響到演算法中的搜尋結構~還有寫程式的查找意義
其實大家有沒有想過
我們雖然人眼可以直接看到B2這格,但說不訂哪天同事的表格欄位不同
比如說
1.Widget A row 跟Widget B對調之類的
2.Sale Price 跟qty數量整個column對調方向
這樣動態的調整會影響到你原來的程式判斷,也失去了自動處理的精神 => 記住,工程師越懶越好
也就是如果透過openxl處理,我們需要透過層層迴圈去查找
from openpyxl import load_workbook
# 載入現有的 Excel 文件
workbook = load_workbook('example.xlsx')
sheet = workbook.active
# 查找 "Widget A" 的位置並修改其價格
for row in sheet.iter_rows(min_row=2): # 從第二行開始,跳過標題行
if row[0].value == 'Widget A': # 假設第一列是產品名稱
row[1].value = 27.00 # 修改價格
break # 找到後退出迴圈
# 保存修改後的工作簿
workbook.save('example_modified_openpyxl.xlsx')
import pandas as pd
# 載入現有的 Excel 文件
df = pd.read_excel('example.xlsx')
# 查找 "Widget A" 並修改其價格
df.loc[df['Product Name'] == 'Widget A', 'Sale Price'] = 27.00
# 保存修改後的 DataFrame 到 Excel 文件
df.to_excel('example_modified_pandas.xlsx', index=False)
總結1.在不知道特定值位置的情況下,openpyxl 需要遍歷整個工作表,而 Pandas 可以通過條件過濾快速找到並修改數據。2.Pandas 提供了更高效和簡潔的數據操作方法,特別是在處理大型數據集時。
openpyxl 刪除 Excel 文件中的工作表,但 Pandas 不支持直接刪除工作表。
from openpyxl import load_workbook
# 載入現有的 Excel 文件
workbook = load_workbook('example.xlsx')
# 列出所有工作表名稱
print("原有工作表:", workbook.sheetnames)
# 刪除特定工作表(例如刪除名為 'Sheet1' 的工作表)
if 'Sheet1' in workbook.sheetnames:
workbook.remove(workbook['Sheet1'])
# 保存修改後的工作簿
workbook.save('example_modified_openpyxl.xlsx')
# 列出修改後的工作表名稱
print("修改後工作表:", workbook.sheetnames)
openpyxl:可以直接使用 remove() 方法刪除指定的工作表,適合需要快速操作 Excel 文件結構的場景。
Pandas:不支持刪除工作表,若需要修改 Excel 結構,建議使用 openpyxl 或其他相關庫。
今天學習到了對檔案文件的CRUD操作
也比較了openxl跟panda好用及不好用、能用跟不能用的範例
優點:
缺點:
優點:
缺點:
openpyxl:
Pandas:
| 操作 | openpyxl | Pandas |
|---|---|---|
| 新增 | 使用 append() 方法直接將行添加到工作表。 |
使用 to_excel() 方法將 DataFrame 寫入 Excel 文件。 |
| 修改 | 直接指定單元格進行修改,或使用 delete_rows() 刪除行。 |
通過 DataFrame 的行和列標籤進行修改,然後寫回 Excel。 |
| 刪除 | 使用 remove() 方法刪除工作表,或 delete_rows() 刪除行。 |
不能直接刪除工作表,但可以通過過濾數據來刪除不需要的行。 |
| 讀取 | 使用 load_workbook() 加載工作簿,並遍歷單元格。 |
使用 read_excel() 將 Excel 數據讀取為 DataFrame。 |
檔案讀取操作那邊,我原本想嘗試使用 with 語句做到檔案的自動讀取/關閉
最後發現不行,因為 openpyxl 和 pandas.read_excel 都不支持 context manager 協議
import openpyxl
with penpyxl.load_workbook('test.xlsx') as workbook:
pass
# TypeError: 'Workbook' object does not support the context manager protocol
使用 openpyxl 時如果需要這個動作,需要自己主動使用 close()
pandas 則是另一種狀況
import pandas as pd
df = pd.read_excel('example.xlsx')
# 這行執行完畢後就自動關閉檔案,不再占用
這部分和使用內建模組讀取 json, txt, csv... 等檔案的操作很不一樣
的確openpyxl 的 Workbook 沒有實現 enter 和 exit 方法,因此不能直接在 with 語句
除非自己定義一個class把方法都包進去處理
感謝補充~!!



 iThome鐵人賽
iThome鐵人賽